

The job market for machine learning engineering is hugely candidate-driven. Statistically, these professionals are the highest paid one in tech — the average salary of a machine learning engineer is $142,900 per year.
The demand for talent among employers is insane and estimated to grow further — research says that 40% of business owners will be adding machine-learning and AI professionals to teams by the end of 2022.
If team leaders are willing to lure candidates in with high paychecks, it’s better to make sure that a machine learning engineer you want to hire is a skilled and reliable one. To assess candidates efficiently and choose the right talent for your team, add these machine learning coding questions to a candidate interview.
10 Basic Machine Learning Interview Questions
When hiring junior machine learning engineers, team leaders should expect the candidates to have a confident command of the most popular ML technologies, Python, Java, and R. Given the widespread use of frameworks like Keras or TensorFlow, making sure engineers know how to use these tools is an intelligent selection criterion.
Other than that, most machine learning algorithms derive from linear algebra and statistics — make sure that the applicant you are screening is no stranger to group theory, Bayesian statistics, and other key concepts.
Here are the basic ML interview questions (and answers) that help find out if a machine learning engineer has a strong CS and math backbone. For more general problem-solving tasks, take a look at this rundown on software engineer interview questions.
#1. Define “classification” and “regression”. Explain the difference between the two.
Classification is a predictive modeling tool used to group input variables into predefined categories “labels”.
The properties of classification are:
- Requires the presence of at least two classes in which inputs will be placed.
- Operates with discrete variables or real values.
- Classification accuracy is the percentage of correct assumptions out of the total number of classifications.
Regression is a predictive modeling method that predicts a value (in most cases, a range) that corresponds to the input variable. It’s often used to deal with data flows — e.g. predicting the fluctuations of the stock market.
#2. Describe the difference between a “test set” and a “training set”.
Although both concepts describe a set of data applied to the algorithm, their objectives are different.
A training set is the volume of data used to train a machine learning project.
On the other hand, a test set is the data used to test a machine learning model that already completed training.
#3. Describe the concept of “ensemble learning”.
Ensemble model is a machine learning technique that suggests combining several base models to create a single efficient model. There are different practices engineers use to implement ensemble learning — let’s go over them briefly:
- Bootstrapping and aggregating (BAGGing) — as the name suggests, the method implies bootstrapping data sets and aggregating several bootstrapped subsets into a single decision tree. Then, an engineer aggregates decision trees as well to create a macromodel.
- Random Forest adds an extra layer of differentiation to data splitting. The algorithm bootstraps a data set in such a way that each decision tree is split based on a set of different features.
#4. What tips do you use to avoid model overfitting?
Simply put, a data model overfitting happens when an algorithm is extremely accurate in predictions for the training set but has a poor precision in real-world conditions (the concept is explained in more detail in “The Signal and the Noise” by Nate Silver).
To detect overfitting and separate the “signal” from the “noise”, ML engineers use the following techniques:
- Comparing an algorithm’s performance on training and testing data sets. If the model has a considerably higher accuracy when processing training data, that’s a red flag for overfitting.
- Cross-validating the model across different types of training data.
- Aiming for simplicity. Up to a certain point, adding new features to the model makes it more accurate and precise. However, there’s a threshold after which every new feature a developer adds is redundant. ML engineers determine such a feature limit for each project mainly through iterative training.
#5. What is the difference between “supervised” and “unsupervised” machine learning?
Supervised machine learning is the process of training the model knowing the desired outputs it should produce. In the process, a machine learning engineer ensures that the real-world outcome matches the predicted one.
Unsupervised machine learning, however, is the process of sharing unlabeled data with the model, allowing it to discover new information on its own. Unlike a supervised learning strategy, this one is unpredictable and can uncover patterns engineers were not aware of at the start of the project.
#6. Why do machine learning engineers use the Naive Bayes classifier?
Before getting into describing the benefits of the classifier, make sure that the candidate has a grasp of conditional probability and the Bayes theorem.
The Naive Bayes classifier has a wide range of applications, from weather prediction and news classifications to diagnosing medical conditions. Here’s why machine learning engineers find it so reliable:
- Easy to understand and apply.
- Doesn’t require large training sets.
- Is a good fit for real-time predictions.
- High running speed.
- Scalable.
- Supports both discrete and continuous values.
#7. Is it good when a model has low bias and high variance? What would your actions be if you created such an algorithm?
Low bias and high variance are the symptoms of model overfitting described above. Such a model is incapable of sorting relevant data “signal” from irrelevant information (“noise”). The main reason why some models have a low bias and high variance is feature redundancy.
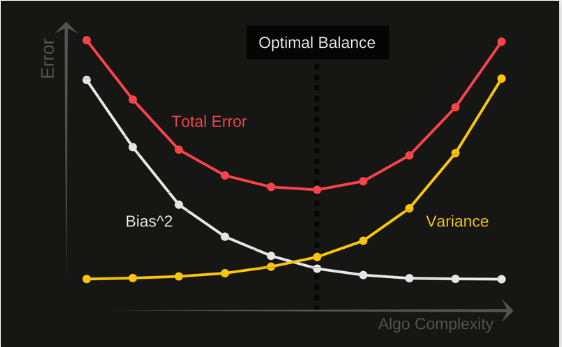
To find a way around the problem, an ML engineer needs to find the balance between bias and variance that reduces the total error.
Total error = Bias^2 + Variance + Irreducible Error.
#8. What is dimensionality reduction?
Dimensionality reduction is the process of trimming down a range of features (columns) in a data set using linear and non-linear methods.
The most popular linear dimensionality reduction methods are:
- Principal Component Analysis, used to reduce the number of features in continuous data sets.
- Factor Analysis — a technique machine learning engineers use to group a lot of variables by pinpointing common factors.
- Linear Discriminant Analysis — finding a way to project data that increases its separability.
#9. How are KNN and k.means clustering methods different?
K-means is a clustering method used for unsupervised deep learning interview questions and projects. It processes the data set and groups it into a k-number of clusters.
Here’s a brief description of how ML engineers classify data using k.means:
- Define the number of clusters (most commonly, by using the Elbow method).
- Assign all data points on a set to a cluster at random.
- Define centroid coordinates for each cluster.
- Determine the distance between data points and the centroid.
- Repeat the last two operations until all data belongs to a cluster.
KNN — (K-Nearest Neighbors) is a clustering algorithm used for supervised learning projects. It uses a set of labeled values to teach the algorithm how to cluster unlabeled data.
Here’s how KNN works:
- Determine the desired number of clusters.
- Calculate the distance between new inputs and labeled data using the Euclidean, Minkowski, or Manhattan method.
- Pinpoint the neighbors with the minimum distance value.
- Assign neighbors to categories by the majority vote.
#10. How does a machine learning engineer analyze the performance of the dataset?
The most common way to analyze the performance of a data set is by measuring its F1 score. It determines an average between the precision and the recall of a model.
An optimal F1 score tends to 1 while a low-accuracy model typically scores closer to 0.
5 Intermediate Machine Learning Interview Questions
An intermediate ML engineer should be skilled in feature selection, training models, and transfer learning. Such a professional should have a good command of data visualization libraries.
Here are the middle machine learning engineer interview questions team leaders should ask:
#1. How do you choose a training set classifier?
The most common data classification criterion is the set size. Smaller training models are less likely to have high bias and low variance — to avoid that, an engineer should consider using a Naive Bayes classifier.
On the other hand, large-size data sets are at risk of overfitting — to classify them efficiently, it’s better to rely on Logic Regression and other high-variance models.
#2. What is LDA?
LDA (short for linear discriminant analysis) is a widely used dimensionality reduction technique. Although the original linear discriminant was applied to solve two-class problems, it was later generalized to handle multiple classes.
LDA allows ML engineers to project a data set on a smaller subset without losing class-discriminatory information.
In post cases, LDA is superior to PCA (principal component analysis). However, there are cases when the latter is more efficient — such as image recognition.
#3. How do you deal with corrupted or missing data?
The key process in handling corrupted or missing data is by identifying the rows of the table that feature such values and replacing them with the new ones. There are plenty of tools that streamline data set maintenance — most developers use Pandas.
The methods used to detect corrupted cells are isnull() and dropna(). To add values to these rows, engineers use the fillna() command.
#4. Explain the difference between model parameters and hyperparameters
The basic difference is that engineers don’t have to specify model parameters — they are derived from input data automatically. That is not the case for hyperparameters — you need to specify them manually.
Model parameters are used as:
- Weights in neural networks
- Linear regression coefficients
- Support vector machine vectors.
Hyperparameters are used as:
- The k-number for KNN clusterization.
- C and sigma parameters for supporting vector machines
- Learning rates for training neural networks.
#5. What is the relationship between foreign and primary keys in SQL?
Since SQL is a primary database language used in machine learning, throwing a few questions into a machine learning interview is always a great idea!
Primary keys are the columns that serve as unique identificators of each row in the table.
Foreign keys are the columns that refer to a primary key in a different table. While primary keys have to be unique, the foreign ones support duplicate values.
5 Advanced Machine Learning Interview Questions
A senior machine learning engineer should be skilled enough to quickly detect algorithm errors and run code reviews. A top-tier developer should know how to lead the team, pairing excellent command of tech tools with a knack for explaining concepts in a straightforward way.
Here a few questions that will help you gauge out whether a senior ML engineer is as skilled as the CV suggests.
#1. What are the benefits and drawbacks of using neural networks?
The benefits of using neural networks are:
- High fault tolerance
- Distributed memory
- Support for models with incomplete knowledge
- Parallel processing
- Unified data storage for the entire network.
As for the limitations of neural networks, these are the most impactful ones:
- Unpredictable behavior
- Reliance on hardware
- Management challenges
- Impossible-to-estimate network duration.
#2. How, in your opinion, our tech team can implement GPT-3?
This question tests how well a machine learning engineer is familiar with innovative technologies. GPT-3 is a language generation model that puts out custom, human-like text. Naturally, the applications of such a powerful tool are countless — let’s name a few:
- Improved search experience (when GPT-3 is paired with NLP).
- Customer service automation and chatbot implementation.
- Removing UX/UI redundancies.
- Automating employee onboarding and streamlining internal processes within the company.
#3. Why do engineers use the encoder-decoder model when working with NLP?
The encoder-decoder model is the cornerstone of machine translation, video captioning, and other NLP applications.
It consists of three blocks:
- Encoder for accepting input elements
- Intermediate vector — encapsulates the information from input elements.
- Decoder — produces output based on the hidden state of the previous element.
This model makes a difference when the input and output sequences have different lengths (e.g. “How are you” and “お元気ですか”)in English and Japanese.
#4. Concisely describe the process of building a machine learning method
By asking the question, a team leader tests a candidate’s ability to not describe the technicalities in too much detail and describe processes in an understandable way.
The answer should have the following structure:
- Determine the goal of the model and align technical specs with business objectives.
- Accumulate data for set generation.
- Clean up the data set.
- Analyze the data using basic exploratory techniques.
- Create a model applying relevant ML algorithms.
- Test the model against a test data set.
#5. Name five books on machine learning engineering a junior developer should read
It’s a great question to wrap up a job interview. After all, you want the candidate to enjoy it, right? What’s the best way to make someone happy if not having them talk about the things they like?
On the other hand, asking engineers to name the books they would suggest to juniors shows how well they understand the learning needs of future teammates. A skilled developer shouldn’t suggest something that’s too technical or requires groundwork in linear algebra or statistics.
The Bottom Line
As you interview machine learning engineers, don’t forget that the candidates are the ones choosing as well. Don’t forget to stay friendly and empathetic, try to avoid one-way questioning, and turn the talk into a dialogue, not an interrogation.
To find machine learning engineers of all levels without paying a dime, consider starting an office abroad. By hiring ML professionals in Latin America and Eastern Europe, business owners broaden the talent pool and discover a lot of cost-cutting opportunities.
Here’s how our team at Bridge helps SME and large-scale company managers connect and manage talent abroad. To find out more about how Bridge works, leave us a message.


